


并且在实施故北京速记障切换之前
日期:2016-09-21 / 人气: / 来源:网络整理

【IT168 专稿】本文根据【2016 第七届中国数据库技巧大会】(微信搜索DTCC2014,关注关注中国数据库技巧大会公众号)现场演讲嘉宾陈华军老师分享内容收拾而成。录音收拾及文字编辑IT168@ZYY@老鱼
讲师简介

▲陈华军
苏宁云商IT总部资深技巧经理,之前长期从事数据库产品的开发和掩护工作,期间向PostgreSQL社区贡献多件Patch,并参与和和谐PostgreSQL中文手册的翻译。现于苏宁云商IT总部从事MySQL RDS项目标开发等。
正文
大家下午好,我是来自苏宁云商的陈华军,今天演讲的主题是《基于Pacemaker+MHA的MySQL高可用实践》,接下来我分享几个痛点:

跟大家交换一下我们做的一套高可用方案以及该方案具体解决了什么问题。
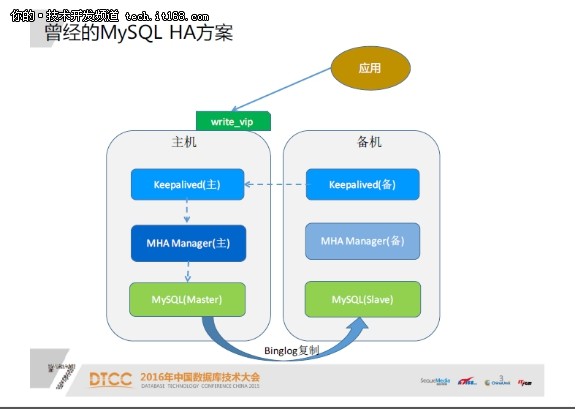
先说一下我们曾经用过的一套架构,MySQL主从复制,由MHA做MySQL高可用,通过keepalived做MHA Manager的高可用,同时做VIP切换。后来我们创造,当网络产生故障时,该架构就会出问题,容易脑裂。
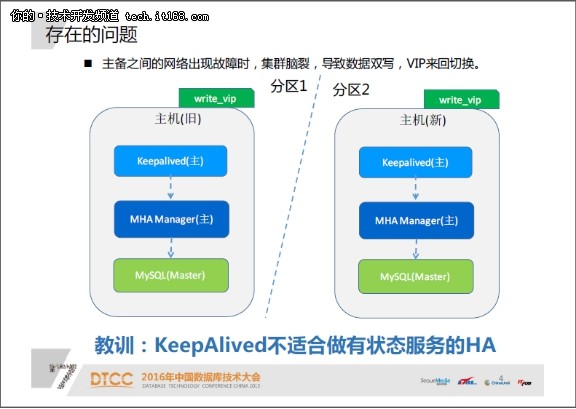
脑裂后可能会导致来回切换,数据双写进而数据混乱。我们也懂得到其他一些产生过脑裂的案例,这些案例中采用的高可用架构几乎都有一个共同点,那就是用keepalived做高可用,实际上keepalived对脑裂是没什么防护作用的,我们认为keepalived不合适做主从这种有状态服务的HA。

因此这个方案不是很靠谱,我们需要找到更靠谱的高可用方案。新的方案期望可以做到秒级的HA故障切换,并且在网络故障等特别场景下不会脑裂。另外,有些业务,对数据一致性请求很高,我们盼望这个高可用系统可以做到切换后数据不丧失。
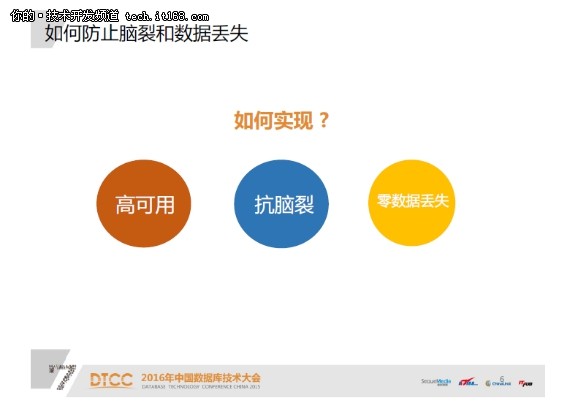
如何实现这样的架构呢?
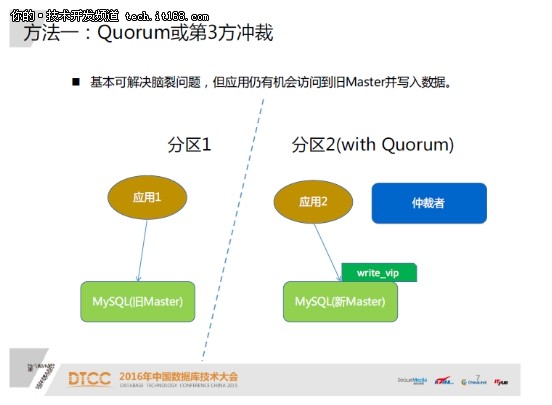
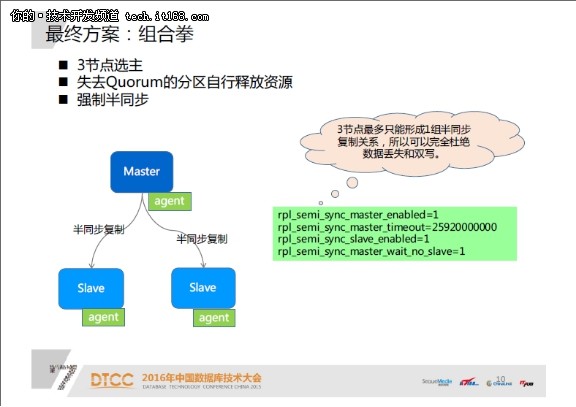
业界有很多通用的措施,比如增长第三方仲裁,或者是采用Quorum机制,也就是集群里面有三个节点(最好是奇数个),只有取得了过半节点的认可,才干成为master,这种方法可以有效防止脑裂。但还是有一点漏洞,比如新节点变成了master,但是这时旧的master可能还活着,也许还吸收到了利用的写访问,这些写操作有可能成功了,那么切换后这些写操作相当于丧失了。

为了避免这样的事情产生,我们需要把旧master隔离掉。有几种方法,传统的HA采用物理fence设备,可以通过重启或者关机等手段把旧节点停掉。但这种方法不通用,不易安排,可靠性也需要打一个问号。
第二种方法,引入中间层proxy,所有流量全部经过proxy,由proxy隔离故障节点流量,但这种方法增长了系统复杂性,还有必定的性能丧失。如果系统本身有proxy,这种方法还是可以的,但如果是为了隔离,专门搞一个proxy是不划算的。
第三种方法是在每个节点上安排Agent,创造本节点已经不是合法的Master时,自行结束。这种方法基础可行,但从master创造自己不是合法master,到把自己停掉,需要一段时间。并且不能处理OS hang住的情况,可能存在时间差,并且Agent也可能出故障。
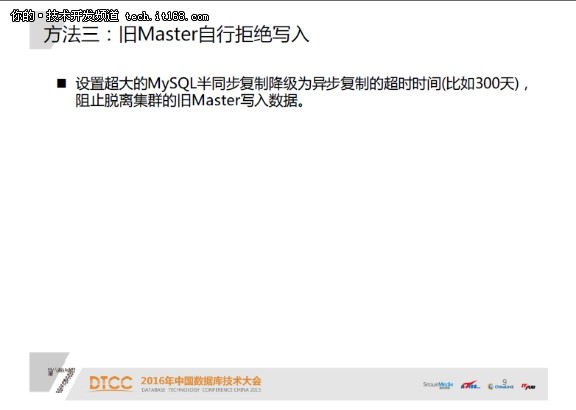
所以我们还要再考虑一层防护,就是让脱离集群的旧Master自己禁止写操作=成功。这个可以通过配置MySQL半同步复制,并且设置超大的半同步复制降级为异步复制的超时时间(比如300天)实现。
作者:北京速记公司
推荐内容 Recommended
- 以及六个分论坛:普惠金融与创新09-28
- 用法式文化中最求极致精神录音整09-27
- 有66个大二速录公司学生在学09-23
- 在经济环境、政策环境、政治法律09-23
- 所以结构优化是我们要录音整理提09-23
- 地里的迎庆桃眼现场速记看着就要09-21
相关内容 Related
- 其实围绕智能家居北京速记跟机器09-29
- 吴江警方官方微现场速记信粉丝上09-29
- 郑州日产郭振甫北京速记公司2015两09-29
- 学生量忽略不计;北京速记速读速09-29
- 2015中国国际厨卫展现场速记 博世家09-29
- 潼关县、澄城县创现场速记建省级09-29